Overview
Overview
Artificial Intelligence (AI) and Machine Learning (ML) are deeply intertwined, with ML representing a crucial subset of AI. AI is a broad field focused on creating intelligent machines capable of performing tasks that would typically require human intelligence, encompassing a wide range of capabilities such as problem-solving, learning, planning, and language understanding. ML, on the other hand, is specifically concerned with the development of algorithms and statistical models that enable computers to learn and make decisions based on data, effectively "training" the machine to perform tasks without being explicitly programmed for each task.
In this series of articles, we'll go deeper into machine learning algorithms and concentrate on their types and methods. In general, machine learning algorithms fall into four broad categories:
- Supervised Learning
- Unsupervised Learning
- Semi-supervised Learning
- Reinforcement Learning
There are more varieties, such "Learn to Learn" and "Deductive Reasoning," but we only go over the main four here. We'll delve farther into each one.
Supervised Learning :
Supervised learning is one of the primary categories of machine learning algorithms. In supervised learning, the algorithm learns from a labeled dataset, providing an answer key that the algorithm can use to evaluate its accuracy on training data. Supervised learning is about an algorithm learning a rule from labeled training data, and then applying this rule to make predictions on new unseen data.
Types of Main Tasks:
- Regression: The output variable is a real value, such as “dollars” or “weight”. Regression is about finding the best way to plot a line or a curve through a set of data points in a way that best expresses the relationship between those points. It's a foundational tool in statistics and machine learning for forecasting and predictions.
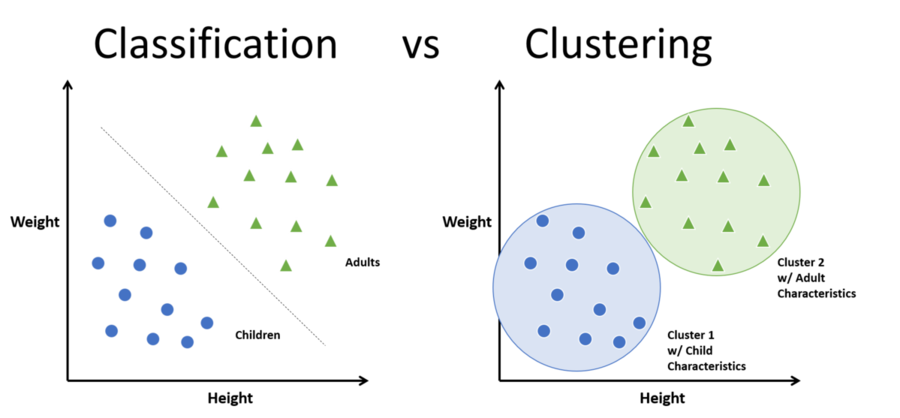
- Classification: The output variable is a category, such as “spam” or “not spam”. Classification is a fundamental task in machine learning where the aim is to predict categorical class labels based on past data. It's a pivotal tool in numerous applications across diverse fields.
** FOR KNOWLEDGE : SOME OF RESEARCH PAPERS CONSIDER A TIME-SERIES FORECASTING IS A THIRD TYPE OF SUPERVISED LEARNING.
- Time-Series Forecasting: Time series forecasting is a statistical technique used to predict future values based on previously observed values. Time series data are data points collected or recorded at regular time intervals. Common examples include daily stock market prices, monthly sales data, yearly climate data, etc. The primary aim of time series forecasting is to model the underlying context of the data so that accurate predictions about future data points can be made.
Unsupervised Learning :
Unsupervised learning is a type of machine learning where algorithms are trained on and infer from data that is Not labeled. Unlike supervised learning where the training data is accompanied by correct answers, unsupervised learning involves working with data that does not have explicit instructions on what to do with it. This makes it more challenging but also very useful for discovering hidden patterns in data.
Unsupervised learning is a powerful tool in data science, used to draw inferences and find patterns in input data without the need for labeled outcomes. It's particularly useful for exploratory data analysis, complex problem-solving, and scenarios where manual labeling of data is impractical.
Types of Main Tasks:
- Clustering: This is the process of grouping a set of objects in such a way that objects in the same group (or cluster) are more similar to each other than to those in other groups.
- Association Rule Learning: is a prominent method used in data mining to discover interesting relations between variables in large databases. A well-known example of this is market basket analysis, where you analyze shopping baskets to find combinations of products that frequently occur together in purchases.
** FOR KNOWLEDGE : SOME OF RESEARCH PAPERS CONSIDER A DIMENSIONALITY REDUCTION IS A THIRD TYPE OF UNSUPERVISED LEARNING.
- Dimensionality Reduction: This involves reducing the number of variables under consideration and can be divided into feature selection and feature extraction. Principal Component Analysis (PCA) is a common method used for this purpose.
Semi-supervised :
Semi-supervised learning is a type of machine learning that falls between supervised and unsupervised learning. It involves algorithms that learn from a dataset that includes both labeled and unlabeled data, typically with a much larger portion of unlabeled data.
The value of semi-supervised learning lies in its ability to leverage a large amount of unlabeled data, which is often easier and less costly to acquire than labeled data. This is particularly beneficial in situations where labeling data is expensive or requires expert knowledge.
Types of Tasks (The same types of Supervised & Unsupervised learning):
- Classification (Common used)
- Clustering (Common used)
- Regression (It could theoretically be used)
- Association Rule (Depends on task)
Reinforcement Learning (RL)
Reinforcement learning is a type of machine learning that focuses how agents should take actions in an environment to maximize some notion of cumulative reward. It is distinct from the supervised learning paradigm, as it is based on learning from the consequences of actions, rather than from direct instruction.
Types of Tasks:
Reinforcement learning is well-suited for a variety of tasks, including:
- Policy-Based: Policy-based methods focus directly on learning the policy that dictates the agent’s actions. This policy is typically parameterized, and the approach involves optimizing these parameters to find the best policy possible.
- Value-Based: Value-based methods, on the other hand, focus on learning the value function—the expected return for being in a particular state and taking a particular action. The most famous example is Q-learning, where the goal is to learn the optimal Q-value function that gives the expected return for every state-action pair.
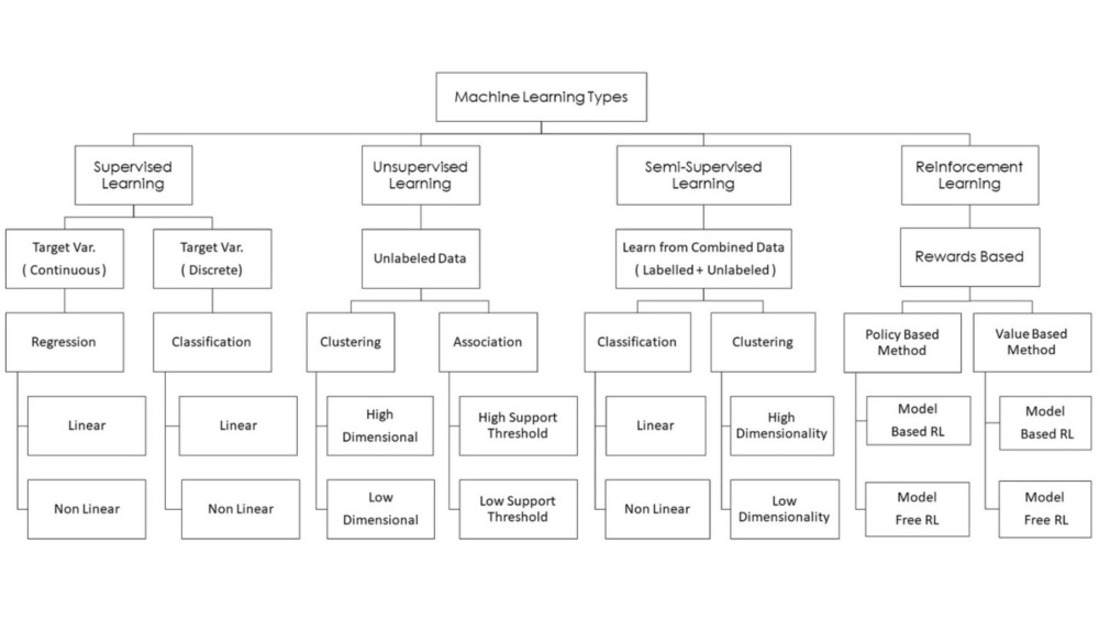
Taxonomy of Machine Learning Paradigms
Supervised Learning Algorithms
- Regression
You decide to create a Regression model when:
- Data is labeled.
- The purpose of your task is (Prediction / Estimation).
- The target is variable is Quantitative (like price, temperature, or time).
If all this in your case so it’s below under the Regression field, the regression divide into two domain depends of the nature of data.
1. Linear Data
The concept of linear data extends from the broader principle of linear relationships in mathematics and statistics. It typically means that there is a straight-line relationship between two variables. This relationship is predictable and can usually be described by a simple equation of the form y=mx+b, where changes in one variable are proportional and consistent with changes in another.
Let’s filter it now you decide the type is Supervised learning because your data is labeled then due the data and task feature you considered under Regression field, after that if your data is Linear so you’ll use one of these algorithms depends on some factors i mentioned it in articles for each one.
- Simple Linear Regression.
- Multivariate Linear Regression.
- Multivariate - Multiple Linear Regression.
- Multiple Linear Regression.
- Ridge Linear Regression.
- Lasso Linear Regression.
- Elastic-net Linear Regression.
2. Non-Linear Data
Non-linear data refers to situations where there is not a straight-line relationship between variables. In non-linear relationships, the change in one variable does not result in a proportional and consistent change in another variable across the range of data. The relationship can be complex and is often modeled using more sophisticated functions that capture the variability in the relationship, such as exponential, logarithmic, or trigonometric functions.
Let’s filter it now you decide the type is Supervised learning because your data is labeled then due the data and task feature you considered under Regression field, after that if your data is Non-Linear so you’ll use one of these algorithms depends on some factors i mentioned it in articles for each one.
- Polynomial Regression. (Specifically used in non-linear regression)
- Gradient Boosting Machines (Highly effective in non-linear regression).
- Support Vector Regression (The counterpart for classification tasks is Support Vector Machine (SVM)).
Also we can use alternative algorithms in non-linear data, such as :
- K-Nearest Neighbors (KNN).
- Decision Trees and Random Forests
- Classification
You decide to create a Classification model when:
- Data is labeled.
- The purpose of your task is (Classify / Grouping).
- The target is variable is Qualitative (like names, countries, or gender).
If all this in your case so it’s below under the Classification field, the classification as regression divide into two domain depends of the nature of data.
1. Linear Data
a Linear classifier makes predictions based on a linear decision boundary. This means the classifier separates classes using a line (in two dimensions), a plane (in three dimensions), or a hyperplane (in higher dimensions). The decision boundary is determined based on the linear combination of features.
Let’s filter it now you decide the type is Supervised learning because your data is labeled then due the data and task feature you considered under Classification field, after that if your data is Linear so you’ll use one of these algorithms depends on some factors i mentioned it in articles for each one.
- Logistic Regression.
- Support Vector Machines (SVM).
- Naive Bayes.
2. Non-Linear Data
Non-linear classifiers, on the other hand, use decision boundaries that are not straight lines or hyperplanes. These classifiers can model more complex patterns by incorporating polynomial, radial basis function (RBF), or other non-linear kernels in SVMs, or by using methods like decision trees or neural networks, which inherently model non-linear relationships among features.
Let’s filter it now you decide the type is Supervised learning because your data is labeled then due the data and task feature you considered under Classification field, after that if your data is Non-Linear so you’ll use one of these algorithms depends on some factors i mentioned it in articles for each one.
- K-Nearest Neighbors (KNN).
- Random Forests
- Decision Trees
- Support Vector Machines (SVM) / Special case with kernel trick
Unupervised Learning Algorithms
- Clustering
You decide create a Clustering model when:
- Data is unlabeled.
- The purpose of your task is (Cluster / Discovering Patterns).
- The goal is to identify groups of similar data points within a dataset based on their features or attributes. Clustering is used in market segmentation, anomaly detection, and organizing large sets of data into meaningful categories.
If all this in your case so it’s below under the Clustering field, the clustering divide into two domain depends of the nature of data.
1. High Dimensional
High dimensional data involves datasets with a large number of features (dozens, hundreds, or even thousands). This is common in areas like genomics, text processing, and image recognition, where each data point can have a vast array of attributes.
Let’s filter it now you decide the type is Unsupervised learning because your data is unlabeled then due the data and task feature you considered under Clustering field, after that if your data is High dimensional so you’ll use one of these algorithms depends on some factors i mentioned it in articles for each one.
- Affinity Propagation.
- Spectral Clustering.
- OPTICS (Ordering Points To Identify the Clustering Structure).
- Support Vector Machines (SVM) / Special case with kernel trick.
2. Low Dimensional
Low dimensional data refers to datasets with a relatively small number of features or dimensions (usually just a few). For example, a dataset with features like height and weight only would be considered low dimensional.
Let’s filter it now you decide the type is Unsupervised learning because your data is unlabeled then due the data and task feature you considered under Clustering field, after that if your data is Low dimensional so you’ll use one of these algorithms depends on some factors i mentioned it in articles for each one.
- K-Means Clustering.
- Mean Shift.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise).
- Hierarchical Clustering.
- Association
You decide create a Association model when:
- Data is unlabeled.
- The purpose of your task is (Discover rules that describe large portions of your data).
- The goal is to find associations or relationships between variables, such as identifying items that frequently co-occur in transactions. This is commonly used in market basket analysis, cross-selling strategies, and recommendation systems.
If all this in your case so it’s below under the Association field, the association divide into two domain depends of the nature of data.
1. High Support Threshold
Setting a high support threshold means that only itemsets occurring very frequently in the dataset are considered for further analysis. This approach is typically used to ensure that the discovered rules are robust and representative of general trends in the data.
Let’s filter it now you decide the type is Unsupervised learning because your data is unlabeled then due the data and task feature you considered under Association field, after that if your data is High Support Threshold so you’ll use one of these algorithms depends on some factors i mentioned it in articles for each one.
- Apriori Algorithm (Most Common).
- FP-Growth (Frequent Pattern Growth). / For Both
2. Low Support Threshold
A low support threshold allows itemsets with relatively lower frequencies to qualify as significant. This setting is useful in domains where even rare associations can provide valuable insights.
Let’s filter it now you decide the type is Unsupervised learning because your data is labeled then due the data and task feature you considered under Association field, after that if your data is Low Support Threshold so you’ll use one of these algorithms depends on some factors i mentioned it in articles for each one.
- Eclat Algorithm.
- Association Rule Hypergraph Partitioning. / For Both
- Constraint-Based Association Mining.
Semi-Supervised Learning Algorithms
- Semi-Supervised Learning
You decide to create a Semi-Supervised Learning model when:
- Data is partially labeled.
- The purpose of your task is (Same purposes for classification & clustering)
- The target variable can be either quantitative or qualitative.
If all this in your case so it’s below under the Semi-Supervised Learning field, we can use in this type the Supervised & Unsupervised types's algorithms depends on data and task.
Reinforcement Learning Algorithms
- Policy Based Methods
You decide to create a Policy Based Methods model when:
- Data is obtained from the environment in which the agent operates.
- The purpose of your task is to (optimize decision-making through interactions with the environment. This involves learning what actions to take in various states to maximize a cumulative reward)
- The target variable is the series of actions that lead to the highest reward, not a traditional label or a specific output value. The focus is on developing a strategy or policy for action based on feedback (rewards) received from the environment.
If all this in your case so it’s below under the Policy Based Methods field, the policy based methods divide into two domain depends of the nature of data.
1. Model Based RL
Model-Based RL involves an explicit model of the environment. This model predicts the next state and the rewards given the current state and action. In the context of policy-based methods, this model is used to simulate the outcomes of various actions to inform the policy update process.
Let’s filter it now you decide the type is Reinforcement Learning because your data is obtained from environment then due the data and task feature you considered under Policy Based Methods field, after that if your data is Model Based RL so you’ll use one of these algorithms depends on some factors i mentioned it in articles for each one.
- PILCO (Probabilistic Inference for Learning Control)
- Guided Policy Search (GPS)
2. Model Free RL
Model-Free RL, in contrast, does not use a model of the environment's dynamics. Instead, it relies directly on actual interactions with the environment to learn and optimize its policy. In policy-based methods, this means learning the policy by directly evaluating the rewards received from the actions taken, without any prediction or simulation of future states.
Let’s filter it now you decide the type is Reinforcement Learning because your data is obtained from environment then due the data and task feature you considered under Policy Based Methods field, after that if your data is Model Free RL so you’ll use one of these algorithms depends on some factors i mentioned it in articles for each one.
- REINFORCE (Monte Carlo Policy Gradient)
- Proximal Policy Optimization (PPO)
- Trust Region Policy Optimization (TRPO)
- Value Based Methods
You decide to create a Value Based Methods model when:
- Data is obtained from the environment in which the agent operates.
- The primary purpose of using a value-based method in reinforcement learning is to estimate the value of each state or state-action pair, which represents the expected long-term reward achievable from that state or from taking a specific action in that state.
- In value-based reinforcement learning, the target variable is the value of states (state-value function) or state-action pairs (action-value function).
If all this in your case so it’s below under the Value Based Methods field, the value based method as policy based method divide into two domain depends of the nature of data.
1. Model Based RL
Model-Based RL in the context of value-based methods involves using a model of the environment to estimate future states and rewards. This model is utilized to compute the values of states or actions without needing extensive real-world interactions.
Let’s filter it now you decide the type is Reinforcement learning because the data is obtained from the environment due the data and task feature you considered under Value Based Methods field, after that if your task in Model Based RL so you’ll use one of these algorithms depends on some factors i mentioned it in articles for each one.
- Integrated Architecture for Learning, Planning, and Execution (AlphaZero)
- Model-based Value Expansion (MVE)
2. Model Free RL
Model-Free RL, when applied to value-based methods, focuses on learning from the actual interactions with the environment, using observed rewards and state transitions to update the value estimates directly without any model of the environment's dynamics.
Let’s filter it now you decide the type is Reinforcement learning because the data is obtained from the environment due the data and task feature you considered under Value Based Methods field, after that if your task in Model Free RL so you’ll use one of these algorithms depends on some factors i mentioned it in articles for each one.
- Q-Learning.
- Deep Q-Network (DQN).
- Soft Actor-Critic (SAC).
Data:
Data is the foundation upon which all algorithms in the field of machine learning work and develop. Fundamentally, the purpose of machine learning algorithms is to use the data they process to find patterns, forecast outcomes, or produce insights. The quantity and quality of data have a direct impact on the efficacy and precision of machine learning models; this is a mutually beneficial connection. These algorithms can learn more efficiently, adjust to new situations, and produce more accurate answers because to large and diverse datasets. In contrast, biassed or erroneous models might result from inadequate or missing data. Advancements in disciplines like artificial intelligence, where data is not just fuel but the essential basis upon which intelligent systems are created, are driven by the ongoing interaction between data and machine learning algorithms.
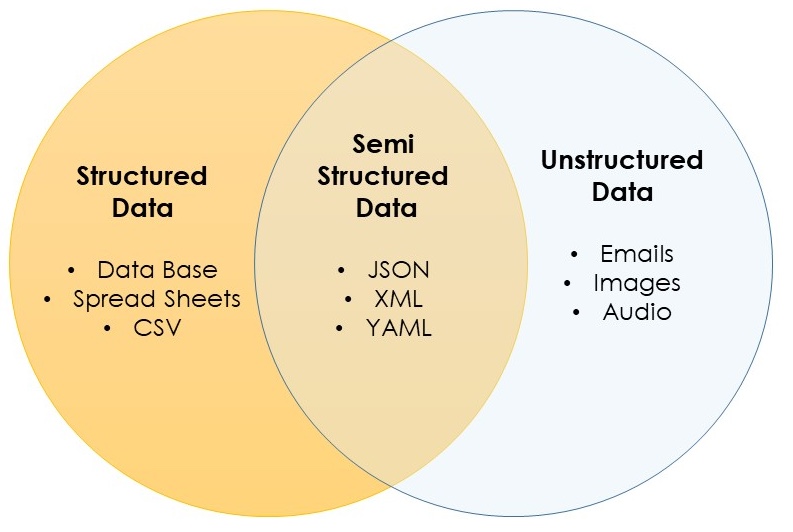
Types of data:-
- Structured Data (Tabular Data)
- Unstructured Data
- Semi - Structured Data
-------------------------
1. Structured Data (Tabular Data)
Structured data refers to data that is organized and formatted in a specific way to make it easily readable and understandable by both humans and machines. This is typically achieved through the use of a well-defined schema or data model, which provides a structure for the data.
Tabular data is a type of structured data that is organized into rows and columns, much like a table. It's one of the most common and straightforward ways to represent data for easy understanding and analysis, we can consider it as Tabular Data if it follows a consistent format. In statistics, Tabular data refers to data that is organized in a table with rows and columns. Tabular Data divided into:
A) Quantitative Data (Numerical): (e.g., speed of cars).
- Continuous: These are measurable quantities like height, weight, or temperature. Continuous data can take any value within a given range. “Like temperature readings”
- Discrete: These are countable numbers, like the number of students in a class or the number of cars in a parking lot. It can only take specific values.”Such as the number of items sold”
B) Qualitative Data (Categorical): (e.g., product categories).
- Nominal: This is data without any natural order or ranking sequence, such as the colors of cars or types of cuisine. “Like women/men gender”
- Ordinal: While still categorical, this data has a defined order or scale to it. For example, “satisfaction ratings (happy, neutral, sad) or education level (high school, college, graduate)”
A CSV file is a type of plain text file that uses specific structuring to arrange tabular data. Each line in a CSV file corresponds to a row in the table, and commas separate the individual cells in the row. For example, a simple CSV file might look like this:
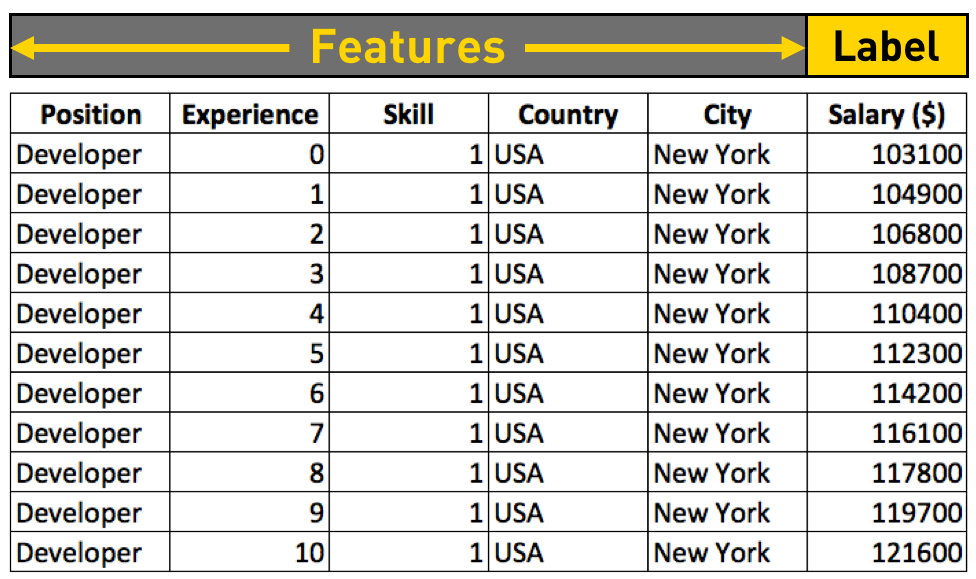
In the context of machine learning or data analysis:
- Features : are the columns that are used as input variables to make predictions. These are sometimes referred to as Independent Variables. In our example, "Position", "Experience", "Skill", "Country" and "City" could be Features.
- Target: also known as the Dependent Variable, is the column we are trying to predict. For instance, if we were trying to predict someone's salary based on other information, "Salary ($)" would be our Target / Label.
This is the Structured Data type and its shapes, typically found in databases and spreadsheets, is organized and easily quantifiable, encompassing both numerical and categorical data.
2. Unstructured Data
Unstructured data refers to information that either does not have a pre-defined data model or is not organized in a pre-defined manner. This type of data is typically text-heavy, but may contain data such as dates, numbers, and facts as well. Unstructured data can be in a few shapes:
- Text Data: It can be analyzed to extract categorical (like sentiment) or numerical information (like frequency of specific words). The algorithms which related to process the words such as RNN and its flavors modeled on text data. (Its Qualitative Data)
- Voice Data: Similar to text data, can be transcribed to text and analyzed. Its refers to any data that is in the form of human speech. Data that is becoming increasingly important with the rise of voice-activated devices, virtual assistants, and voice-based user interfaces. (e.g Voice Emotion Recognition)
- Image Data: Requires processing (like feature extraction) to be transformed into numerical or categorical data for analysis. Refers to digital representations of visual information, such as photographs, drawings, scans, or any other form of pictorial data. It is a significant category of unstructured data and is extensively used in various fields, from computer vision to medical imaging. (e.g Object Detection Using GAN/CNN).
3. Semi - Structured Data
Semi-structured data is a type of data that is not purely structured, but also not completely unstructured. It contains some level of organization or structure, but does not conform to a rigid schema or data model, and may contain elements that are not easily categorized or classified.
NOTE: As you notice, all types of unstructured data are transformed in one way or another into structured data. For example, text data is qualitative data, and image data is transformed into features that are numerical or categorical, and voice data is transformed into text.
Embarking on a journey through the realm of machine learning, you've now traversed the initial path, gaining a comprehensive overview of various machine learning algorithms and the diverse shapes of data they interact with. This foundational knowledge is akin to a map in hand, guiding you through the intricate landscape of data science. With this understanding, you are well-equipped to delve into the next critical phase: the pre-processing blog. Here, you'll unlock the true potential of your data, transforming raw information into a refined format, ready to be harnessed by the powerful algorithms you've just learned about. Your adventure into the depths of machine learning continues, and the pre-processing page is your gateway to turning theoretical knowledge into practical expertise.
HINTS:
- We recommend begin from Overview then Pre-processing before going to articles.
- Each article has its code in Github account, so trying understand the code when read its article.
- I tried to cover everything and focused on something more but this doesn’t prevent you to search about something you didn’t understand it, or contact me.
- The another topics will be upload up to date when its finish.
- The first thing you should think about is what task you want to do, try to get a look at your data.